



Abstract
Consistent text-to-image (T2I) generation seeks to produce identity-preserving images of the same subject across diverse scenes, yet it often fails due to a phenomenon called identity (ID) shift. Previous methods have tackled this issue, but typically rely on the unrealistic assumption of knowing all target scenes in advance. This paper reveals that a key source of ID shift is the native correlation between subject and scene context, called scene contextualization, which arises naturally as T2I models fit the training distribution of vast natural images. We formally prove the near-universality of this scene-ID correlation and derive theoretical bounds on its strength. On this basis, we propose a novel, efficient, training-free prompt embedding editing approach, called Scene De-Contextualization (SDeC), that imposes an inversion process of T2I’s built-in scene contextualization. Specifically, it identifies and suppresses the latent scene-ID correlation within the ID prompt’s embedding by quantifying the SVD directional stability to adaptively re-weight the corresponding eigenvalues. Critically, SDeC allows for per-scene use (one scene per prompt) without requiring prior access to all target scenes. This makes it a highly flexible and general solution well-suited to real-world applications where such prior knowledge is often unavailable or varies over time. Experiments demonstrate that SDeC significantly enhances identity preservation while maintaining scene diversity.
Introduction
This paper investigates the problem of ID shift in text-to-image (T2I) generation—where the same subject’s appearance changes across different generated scenes. While T2I models like Stable Diffusion excel at visual fidelity, they struggle to maintain consistent identity in narrative or sequential tasks. The authors attribute this to scene contextualization, a bias caused by the model’s learned association between subjects and typical scene contexts. To address this, they introduce Scene De-Contextualization (SDeC), which mathematically reverses contextual bias through eigenvalue optimization using SVD. SDeC decouples identity embeddings from scene correlations, allowing consistent generation without needing full target-scene supervision. Experiments show that SDeC improves identity preservation and scene diversity across various models and tasks.
Visualization of how scene contextualization affects subject identity consistency in text-to-image generation.

Left: The attire of the subject varies with the site. Right: The subject’s clothing changes with the season.
Scene Contextualizaztion
We propose SDeC (Scene De-Contextualization), which mitigates scene influence by identifying and suppressing the latent scene–ID correlation subspace in ID embeddings. Using SVD-based optimization and eigenvalue modulation, SDeC enhances stable directions and reconstructs a refined identity representation, improving identity consistency in generated images.
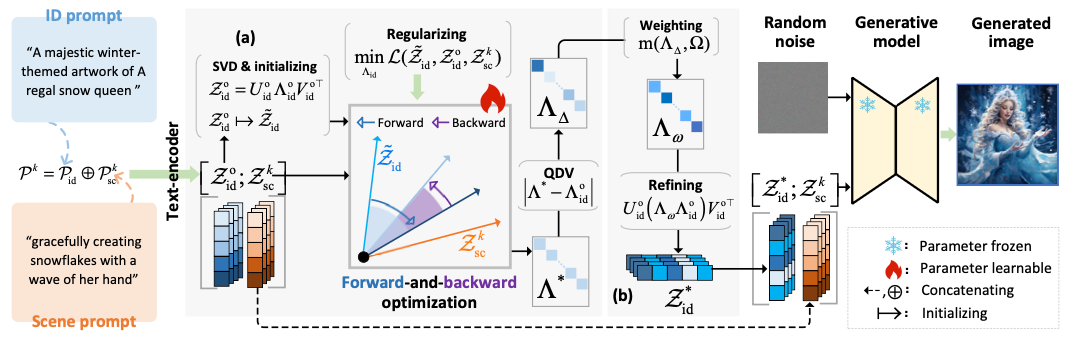
Comparison To Current Methods





Integrating With Other Generative Tasks
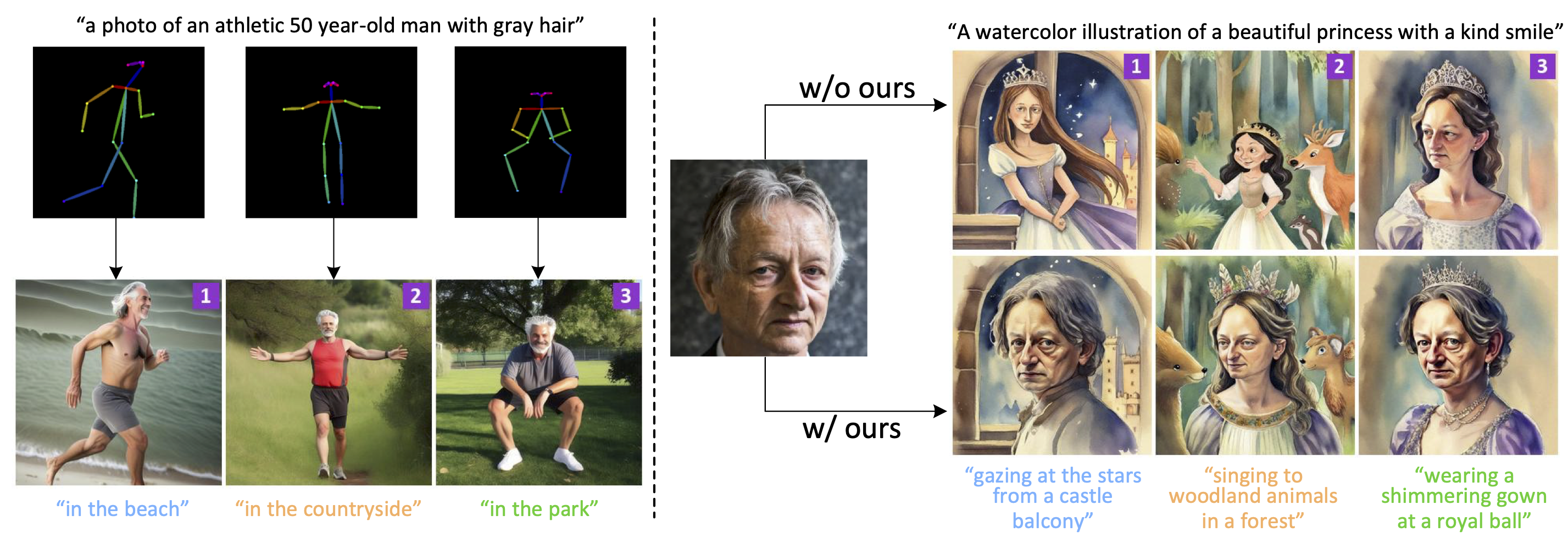
Consistent story generation with multiple subjects

Generality To Base Generative Model



